



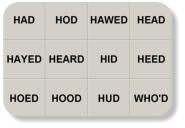
Vowel Recognition Test:
Vowel recognition was measured in a 12-alternative identification paradigm. The
vowel set included 10 monophthongs and 2 diphthongs, presented in a /h/-vowel-/d/
context (heed, hid, head, had, who'd, hood, hod, hud, hawed, heard, hoed, hayed).
The tokens for vowel recognition test were digitized natural productions from 5 men
and 5 women, for a total of 120 tokens for standard test or 2 men and 2 women, for a
toal of 48 tokens for express test.
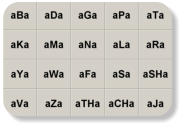
Consonant Recognition Test:
Consonant recognition was measured in a 20-alternative identification paradigm. The
consonant set included /b d g p t k m n l r y w f s sh v z th ch j/, presented in an /a/-
consonant-/a/ context. Consonant tokens consisted of digitized natural productions
from 5 men and 5 women, for a total of 200 tokens for standard test. The tokens for
the consonant recognition test were digitized natural productions from 2 men and 2
women, for a total of 80 tokens.

Voice Gender Recognition Test:
Voice gender recognition was measured in a 2-alternative identification paradigm.
The tokens were the same as those used in the vowel recognition. In the other
words, there are 120 tokens for the standard test and 48 tokens for the express test.

Melodic Contour Identification Test
Melodic Contour Identification was measured in a 9-alternative identification
paradigm. The contour set included 9 patterns, representing simple pitch contours
(e.g., "rising," "falling," "flat") and changes in pitch contour (e.g., "rising- falling,"
"falling-rising," "rising-flat," "flat-rising," "flat-falling," "falling-flat"). The melodic
sequences were generated in relation to a "base note," (i.e., the lowest note in the
melody); The interval between successive notes in the melodic sequence is varied
between 1 and 5 semitones. For the standard MCI test, a total of 135 melodic
sequences were generated (9 patterns x 3 base x 5 inter-note distances). For the
express test, only one base note is used, resulting in a total of 45 tokens.
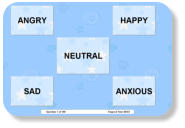
Vocal Emotion Recognition Test
Vocal emotion recognition was measured in a 5-alternative identification paradigm.
The emotion set included 5 target emotions (angry, happy, sad, anxious, and
neutral). Vocal emotion tokens consisted of 50 digitized natural produced sentences
(10 sentences, each with 5 emotions) from one female and one male, for a total of
100 tokens for standard test and 40 tokens for express test (with 4 sentences only).



Basic Speech Perception Test Module
Basic module covers five commonly used closed-set speech recognition test, including vowel
recogntion, consonant recognition, voice gender recognition, melodic contour identification, and
vocal emotion recogntion. Basic module also have two testing groups. One is the standard test
and the other is the express test. The only difference is that express test contains less stimuli
so the test takes less time but also less reobust. The detailed description of each test is shown
as follows.

Internet-based Computer-Assisted Speech Testing












